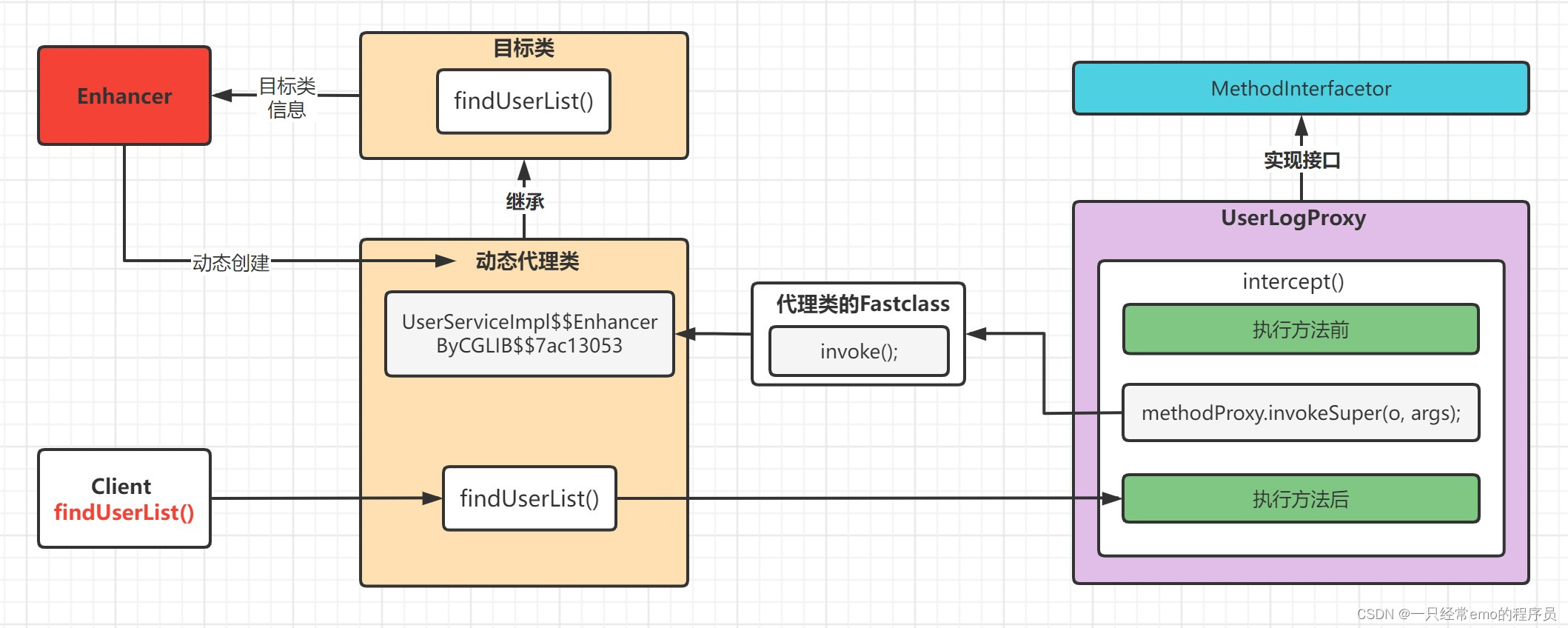
滚动轴承是机械设备中关键的零部件之一,其可靠性直接影响了设备的性能,所以对滚动轴承的剩余使用寿命(RUL)进行预测是十分必要的。目前,如何准确地对滚动轴承剩余使用寿命进行预测,仍是一个具有挑战的课题。对滚动轴承剩余寿命评估过大或过小均存在不良后果,轴承寿命的提前截止会导致严重的事故,而提前更换轴承则会增加设备维护成本。目前建立轴承寿命预测模型需要完整寿命周期的轴承数据作为支撑,在实际运用过程中,轴承大多数安装在密封的环境中,无法对轴承的状态进行直接观察,所以拥有完整寿命周期数据的轴承是较少的,这为提高轴承寿命预测精度带来了一定困难。同时轴承实时数据采集受到传感器安装条件的限制,在某些情况下,只能等待设备运行至固定的时间点,才能采集轴承的数据,存在无法获得轴承完整寿命周期数据的问题。目前预测的主要方法是对采集的滚动轴承运行实时数据进行分析,构建机理模型、经验模型、大数据模型等做出相应判断,最后预测出轴承剩余使用寿命。
该代码为Python环境下基于指数退化模型和LSTM自编码器的滚动轴承剩余寿命预测,所用数据集为NASA FEMTO Bearing 公开数据集,试验台如下:

所用模块版本如下:
tensorflow=2.8.0
keras=2.8.0
sklearn=1.0.2部分代码如下:
import os,time
import scipy.io
import scipy.stats
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
#import sklearn.external.joblib as extjoblib
import joblib
#from sklearn.externals import joblib
import seaborn as sns
sns.set(color_codes=True)
print(tf.__version__)
#%%
#TensorFlow 设置
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
from numpy.random import seed
import tensorflow as tf
#tf.random.set_seed(x)
#tf.logging.set_verbosity(tf.logging.ERROR)
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
from keras.layers import Input, Dropout, Dense, LSTM, TimeDistributed, RepeatVector
from keras.models import Model
from keras import regularizers
# set random seed
seed(10)
tf.random.set_seed(10)
#set_random_seed(10)
# In[ ]:
#载入文件,并创建 RMS 数据框
PHM_path = 'PHM'
PHM_bearing_files = [os.path.join(PHM_path,file) for file in os.listdir(PHM_path)]
#定义特征提取函数
def get_FPT(h2):
kurt_list = []
rms_list = []
for i,row in enumerate(h2):
kurt = scipy.stats.kurtosis(row)
kurt_list.append(kurt)
rms = np.mean(row**2)**0.5
rms_list.append(rms)
weight = np.concatenate([np.linspace(5, 4.5, 100),
np.linspace(4.5, 4, 500),
np.linspace(4, 3, 2000),
np.linspace(3, 3, 3000)])
w = weight[i]
kurt_c = kurt > np.mean(kurt_list)+w*np.std(kurt_list)
rms_c = rms > np.mean(rms_list) +w*np.std(rms_list)
if kurt_c and rms_c:
break
return i
#mat文件转换为数组
def mat_to_arr(file):
h = scipy.io.loadmat(file)['h'].reshape(-1)
h2 = h.reshape(-1, int(len(h)/2560))
# print(len(h)/2560)
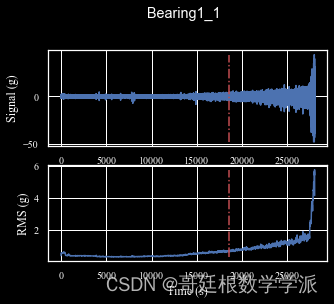
rms = np.array( [np.mean(i**2)**0.5 for i in h2] )
rms = np.convolve(rms,[0.3,0.4,0.3],mode='same')
return h,rms
# In[ ]:
df = pd.DataFrame()
plt.style.use(['dark_background'])
for file in PHM_bearing_files[:17]:
h,rms = mat_to_arr(file)
df[file[-14:-4]]=rms
df = df[['Bearing1_1','Bearing1_3','Bearing1_4']]
df=df[:-1]
print(df)
#%%
#训练集和测试集划分
train = df[0:1500]
test = df[1501:]
print("Training dataset shape:", train.shape)
print("Test dataset shape:", test.shape)
#%%
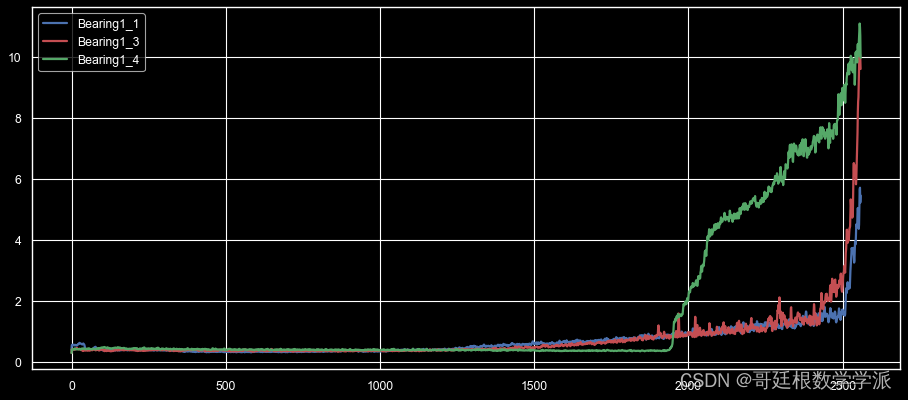
#绘图
fig, ax = plt.subplots(figsize=(14, 6), dpi=80)
cols = df.columns.values
ax.plot(train['Bearing1_1'], label='Bearing1_1', color='b', animated = True, linewidth=2)
ax.plot(train['Bearing1_3'], label='Bearing1_3', color='r', animated =True, linewidth=2)
ax.plot(train['Bearing1_4'], label='Bearing1_4', color='g', animated =True, linewidth=2)
plt.legend(loc='upper left')
ax.set_title('Bearing Sensor Training Data', fontsize=16)
plt.show()
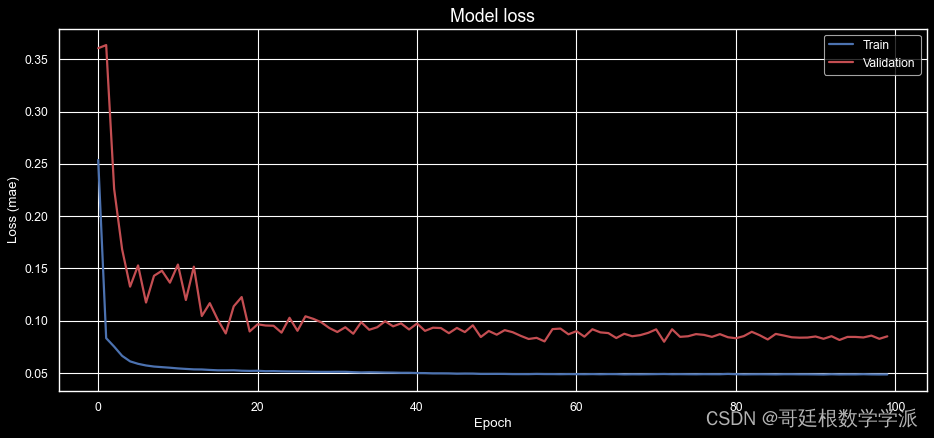
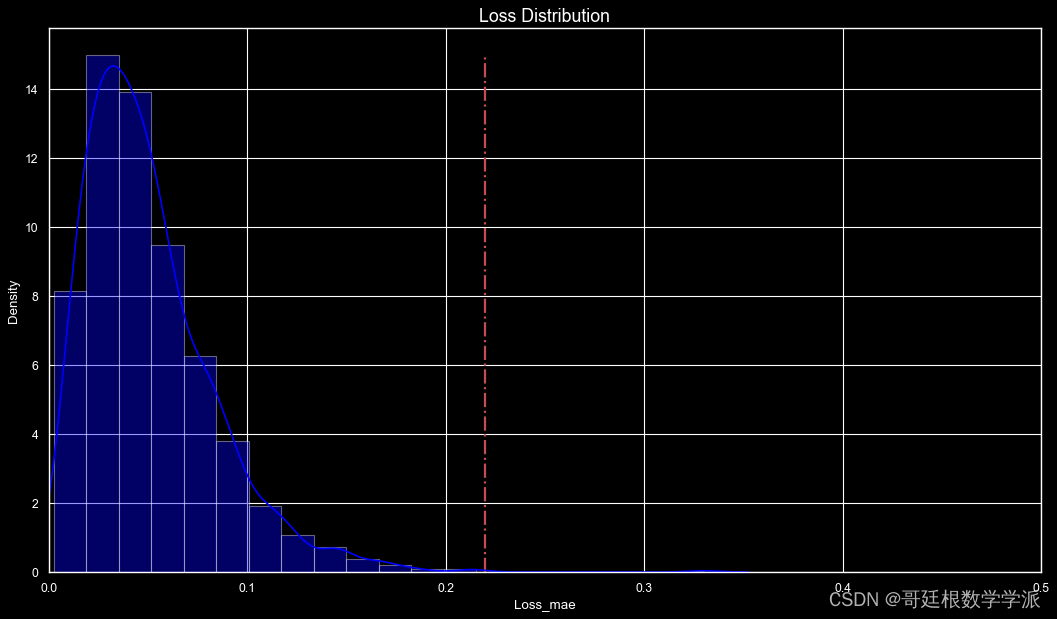
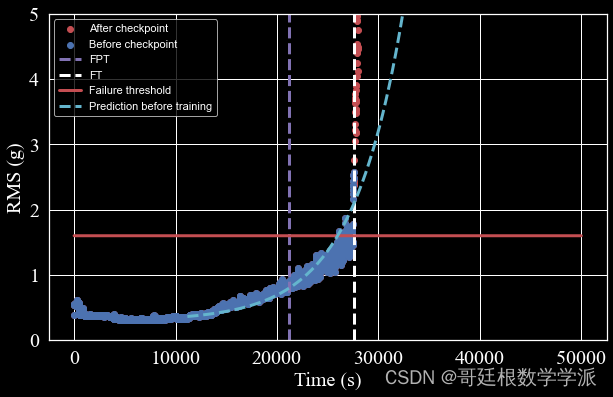
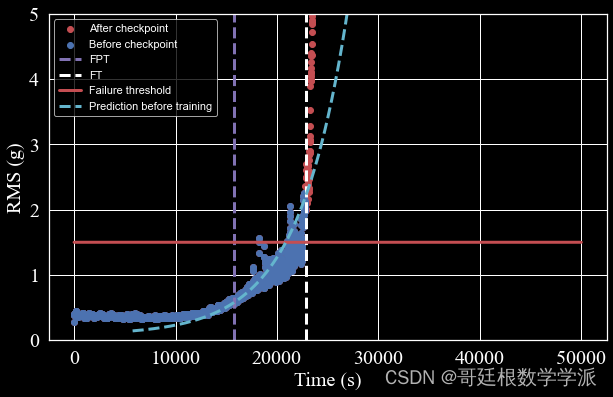
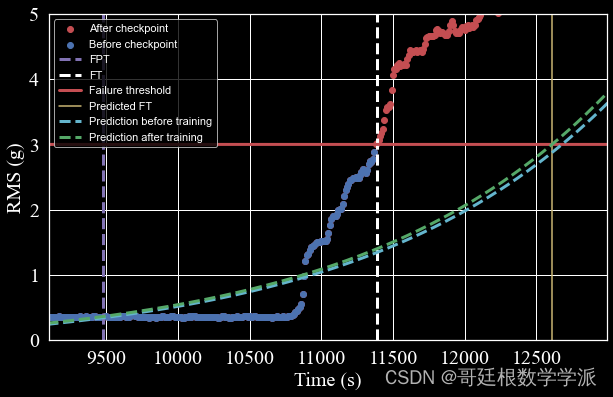
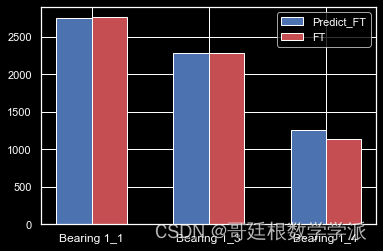
出图如下:







工学博士,担任《Mechanical System and Signal Processing》审稿专家,担任
《中国电机工程学报》优秀审稿专家,《控制与决策》,《系统工程与电子技术》,《电力系统保护与控制》,《宇航学报》等EI期刊审稿专家。
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。